
Alex
9/19/2024

In der heutigen digitalen Welt werden Speech-Chat-Bots immer populärer. Diese Technologie ermöglicht es Unternehmen, auf eine neue Art und Weise mit ihren Kunden zu interagieren, indem sie menschliche Sprache versteht und darauf reagiert. Doch wie funktioniert ein Speech-Chat-Bot genau? Welche technologischen Prozesse stehen dahinter, und warum sind Latenz und Präzision dabei besonders herausfordernd? In diesem Blog-Post werden wir die Funktionsweise eines Speech-Chat-Bots im Detail durchleuchten, um ein tieferes Verständnis der zugrundeliegenden Technologie zu vermitteln und die damit verbundenen Herausforderungen zu erklären.
Ein Speech-Chat-Bot ist eine Anwendung der künstlichen Intelligenz (KI), die es Nutzern ermöglicht, durch gesprochene Sprache mit einem System zu interagieren. Diese Technologie kombiniert Spracherkennung (Speech-to-Text, S2T), natürliche Sprachverarbeitung (Natural Language Processing, NLP) und Text-zu-Sprache-Umwandlung (Text-to-Speech, T2S), um gesprochene Anfragen zu verstehen, zu verarbeiten und darauf zu antworten.
Die Hauptkomponenten eines Speech-Chat-Bots sind:
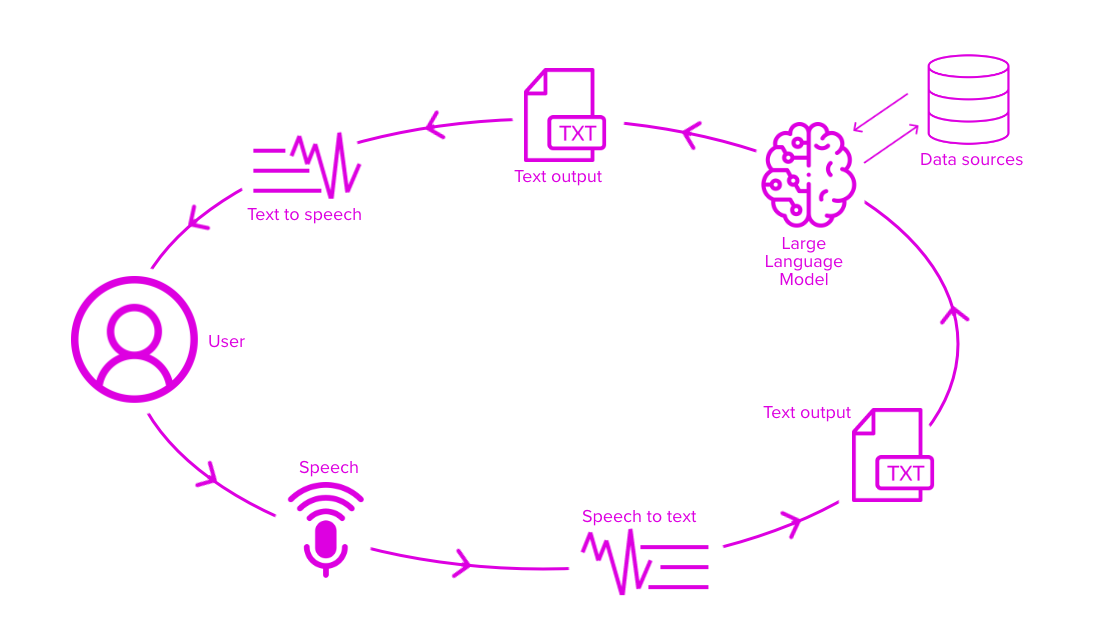
Um die Funktionsweise eines Speech-Chat-Bots besser zu verstehen, ist es hilfreich, die einzelnen Schritte zu betrachten, die während einer typischen Interaktion ablaufen.
Der erste Schritt in einer Interaktion mit einem Speech-Chat-Bot ist die Umwandlung der gesprochenen Sprache des Nutzers in Text. Dieser Prozess erfordert die Verwendung fortschrittlicher maschineller Lernmodelle und Algorithmen für die Spracherkennung.
Dieser Prozess kann je nach Komplexität der Anfrage, der Sprachqualität und der Netzwerkgeschwindigkeit unterschiedlich lange dauern. Hier zeigt sich bereits die erste Herausforderung: Latenz. Je schneller der Speech-Chat-Bot die Sprache in Text umwandeln kann, desto flüssiger und natürlicher wirkt die Interaktion für den Nutzer.
Sobald die gesprochene Sprache in Text umgewandelt ist, verwendet der Speech-Chat-Bot NLP-Algorithmen, um die Bedeutung der Anfrage zu verstehen. Dieser Schritt umfasst mehrere Teilprozesse:
Dieser NLP-Schritt ist ebenfalls zeitintensiv und kann zu Verzögerungen führen. Eine weitere Herausforderung besteht hier in der Präzision: Der Speech-Chat-Bot muss die Absicht des Nutzers korrekt identifizieren und relevante Informationen extrahieren, um die richtige Antwort zu generieren.
Nach der Analyse der Anfrage muss der Bot eine passende Antwort generieren. Dieser Schritt kann auf verschiedene Weisen durchgeführt werden:
Die Herausforderung in diesem Schritt besteht darin, sicherzustellen, dass die bereitgestellten Informationen sowohl korrekt als auch relevant sind. GenAI-Lösungen (Generative AI bieten hier immense Vorteile, aber sie bergen auch das Risiko, ungenaue oder irrelevante Antworten zu geben.
Nachdem die Antwort generiert wurde, wird sie durch die T2S-Komponente in gesprochene Sprache umgewandelt:
Auch hier kann es zu Latenz kommen, da die Umwandlung von Text in Sprache Rechenleistung erfordert. Eine möglichst geringe Verzögerung ist entscheidend, um die Nutzererfahrung zu optimieren.
Eine der größten Herausforderungen bei der Entwicklung eines Speech-Chat-Bots ist die Latenz, d.h. die Verzögerung, die zwischen der Eingabe des Nutzers und der Ausgabe des Systems auftritt. Mehrere Faktoren tragen zur Latenz bei:
Jede dieser Verzögerungen kann die Gesamtleistung des Bots beeinträchtigen. Um die Latenz zu minimieren, müssen Entwickler sicherstellen, dass die zugrunde liegende Infrastruktur optimiert ist und dass die verwendeten Modelle und Algorithmen effizient arbeiten.
Es gibt verschiedene Ansätze, um die Latenz zu minimieren:
Neben der Latenz ist die Präzision ein zentrales Anliegen bei der Entwicklung von Speech-Chat-Bots. Der Bot muss in der Lage sein, die Absicht des Nutzers korrekt zu verstehen und eine relevante, genaue Antwort zu liefern. Dies ist oft eine schwierige Aufgabe, da natürliche Sprache komplex und mehrdeutig sein kann.
Die Entwicklung eines effektiven Speech-Chat-Bots erfordert ein sorgfältiges Gleichgewicht zwischen Latenz und Präzision. Während eine schnelle Antwortzeit entscheidend ist, um die Nutzererfahrung zu verbessern, ist es ebenso wichtig, dass die bereitgestellten Informationen korrekt und relevant sind. Unternehmen müssen daher in moderne Technologien und Infrastrukturen investieren, um diese beiden Herausforderungen zu meistern.
Zusammengefasst ist die Implementierung eines Speech-Chat-Bots kein triviales Unterfangen. Es erfordert eine durchdachte Planung, den Einsatz fortschrittlicher KI-Modelle und kontinuierliche Optimierung, um sicherzustellen, dass der Bot sowohl schnell als auch präzise arbeitet. Nur so kann er den Erwartungen der Nutzer gerecht werden und einen echten Mehrwert bieten.
Unternehmen, die in die Entwicklung und Optimierung von Speech-Chat-Bots investieren, können erheblich davon profitieren, indem sie ihre Kundenkommunikation verbessern, effizientere Arbeitsabläufe schaffen und neue Geschäftsmodelle erschließen. Die fortlaufende Weiterentwicklung dieser Technologie, insbesondere durch Lösungen wie izzNexus, die Unternehmen ermöglichen, KI mit ihren eigenen Datenquellen zu verbinden, wird entscheidend dazu beitragen, die Herausforderungen der Latenz und Präzision zu überwinden. izzNexus bietet eine vollständige Integration von Speech-to-Text und Text-to-Speech Technologien und sie kann als vielseitiges Feature genutzt werden. Diese Funktion ist besonders vorteilhaft für Anwendungen, die eine barrierefreie Interaktion, Sprachsteuerung oder Automatisierung von sprachbasierten Aufgaben erfordern.
Die Integration von KI-Lösungen, die sowohl in der Lage sind, Echtzeit-Sprachverarbeitung durchzuführen als auch auf eine breite Datenbasis zurückzugreifen, wird in den kommenden Jahren zunehmend an Bedeutung gewinnen. Unternehmen sollten sich daher frühzeitig mit diesen Technologien auseinandersetzen, um ihre Potenziale voll auszuschöpfen.