Beyond RAG: Next-gen Retrieval Architekturen für KI mit eigenen Daten
10/29/2025

Alex
Alle reden über RAG, als wäre es das Nonplusultra der GenAI-Welt.
„Einfach deine Dokumente vektorisieren, in eine Datenbank kippen – und zack, die KI kennt dein Unternehmen!“
Klingt gut. Funktioniert aber nur auf PowerPoint-Folien.
Denn RAG ist kein Zauberspruch. Es ist ein cleverer Ansatz – aber kein fertiges System. Wenn du versucht hast, das Ding in der echten Welt zu skalieren – über mehrere Datenquellen, Dateitypen oder gar Standorte hinweg – dann weißt du, dass es schnell an seine Grenzen kommt.
Also: Zeit, über den Tellerrand zu schauen.
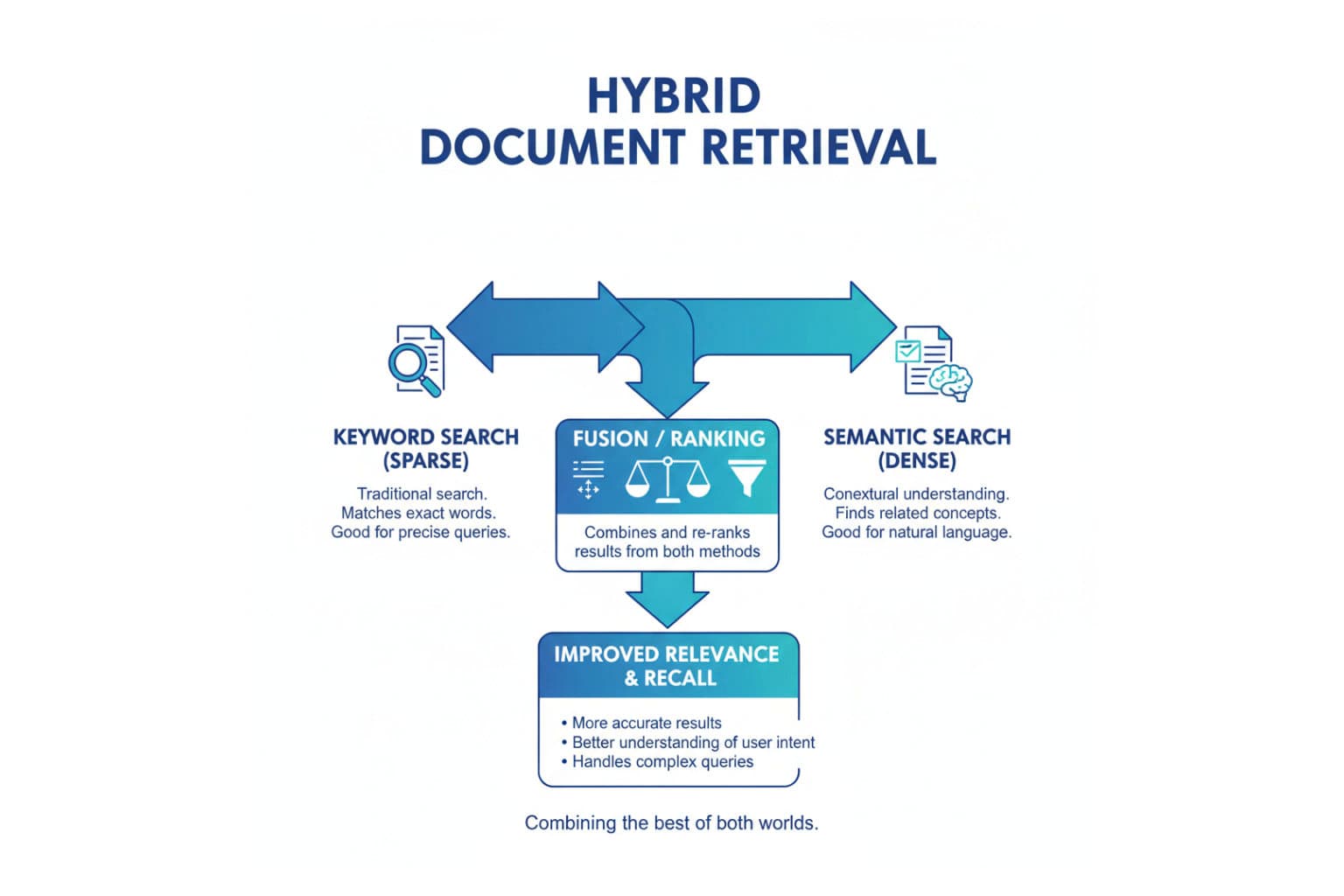
Hybrid Retrieval: Wenn ein Hirn nicht reicht
Vektorsuche ist super, wenn du Bedeutung suchst.
Keyword-Suche ist super, wenn du Genauigkeit willst.
Kombinier beides – und du bekommst ein System, das versteht, was du meinst, und weiß, was du wirklich sagst.
Hybrid Retrieval kombiniert:
- Symbolische Suche (Keywords, Metadaten, Filter) für exakte Treffer.
- Semantische Suche (Vektoren, Embeddings) für Kontext und Bedeutung.
- Graph Retrieval, um Beziehungen zwischen Entitäten zu verstehen – also wer mit wem zu tun hat, was wovon abhängt und woher Wissen eigentlich kommt.
Das ist der Moment, in dem dein Unternehmens-RAG endlich lebt: Es versteht dein Organigramm, deine Produktstruktur, deine Lieferkette.
Es ist kein „Chat über PDFs“ mehr – sondern „Chat über Wissen“.
Multi-Modal Retrieval: Weil nicht alles Text ist
Unternehmen lieben PDFs. Leider hört da die Welt nicht auf.
In der Realität gibt’s:
- Bilder (Diagramme, Pläne, Designs)
- Audio (Meetings, Interviews)
- Video (Trainings, Demos)
- Tabellen, JSON, Code, CAD-Dateien und alles dazwischen.
Next-Gen Retrieval ist agnostisch gegenüber Dateiendungen.
Es kombiniert verschiedene Embeddings in einem gemeinsamen semantischen Raum.

Heißt: Wenn du fragst „Was haben wir eigentlich zum Rollout in Stuttgart beschlossen?“, kommen die Infos nicht nur aus einem Protokoll, sondern auch aus Präsentationen und Slack-Chats.
So fühlt sich eine GenAI nicht mehr wie ein Suchfeld an – sondern wie ein echter Kollege.
Retrieval unter Latenz-Druck: Weil keiner wartet
Niemand wartet zehn Sekunden auf „Smartness“.
Jede Millisekunde zählt – vor allem, wenn dein Copilot oder Chatbot live läuft.
Das Dilemma:
- Mehr Kontext = bessere Antworten = langsamer.
- Weniger Kontext = schnell = dümmer.
Next-Gen Retrieval löst das mit Caching, Pre-Ranking und intelligentem Batching.
Es merkt sich, was häufig gefragt wird, was „heiße Daten“ sind, und liefert zuerst eine schnelle Antwort – die im Hintergrund smarter wird.
Wie ein Mensch, der beim Reden weiterdenkt – nur ohne Ausreden.
Retrieval als Infrastruktur: Der echte nächste Schritt
RAG ist keine einmalige Spielerei.
Es wird gerade zur Infrastruktur.
Das heißt:
- Einheitliche Retrieval-APIs für alle Teams
- Security und Berechtigungen direkt in Embeddings integriert
- Versionierung, Audit-Trails und Governance, damit du weißt, woher eine Antwort kam
Wenn Retrieval zur Plattform wird, bekommen alle Apps, Bots und Analysten Superkräfte – ohne jedes Mal neu zu erfinden, wie man Daten findet.
Fazit
RAG war der Türöffner.
Aber echte Unternehmensintelligenz entsteht nicht durch eine einzige Retrieval-Methode – sondern durch das Orchestrieren vieler.
Wenn du 2025 noch stolz sagst, dass du „RAG nutzt“, ist das ungefähr so beeindruckend wie „Wir haben jetzt WLAN im Büro.“
Nett. Aber bitte.
Die eigentliche Frage ist: Wie weit bist du schon darüber hinaus?
Bleibe immer auf dem Laufenden!